


Jupyter Notebookでscikit-learnを使って機械学習してみる
カテゴリ:Pythonの話
こんにちは伊神です!
この記事ではJupyter Notebookでscikit-learnを使って機械学習する方法を紹介します。
Pythonは様々な用途で使われますが、ディープラーニングや分析などの機械学習が強いです。その機械学習についてscikit-learnライブラリを用いてご紹介します。
また、弊社ではWebプロモーション成功事例集をまとめた限定資料を無料で配布しています。
Webマーケティングに興味がある方は、下記ページより目を通してみてください。
Jupyter Notebook
Jupyter Notebookについてはこちらを参考にして下さい。
またwebで集客する方法を別の記事にまとめております。
詳しく解説しているので、web集客について深く知りたい方は、ぜひこちらもご覧ください。

scikit-learn
scikit-learnはpythonの機械学習ライブラリです。
機械学習の有名アルゴリズムを多く含んでいて、機械学習に必要なデータ処理などのツールも提供しています。
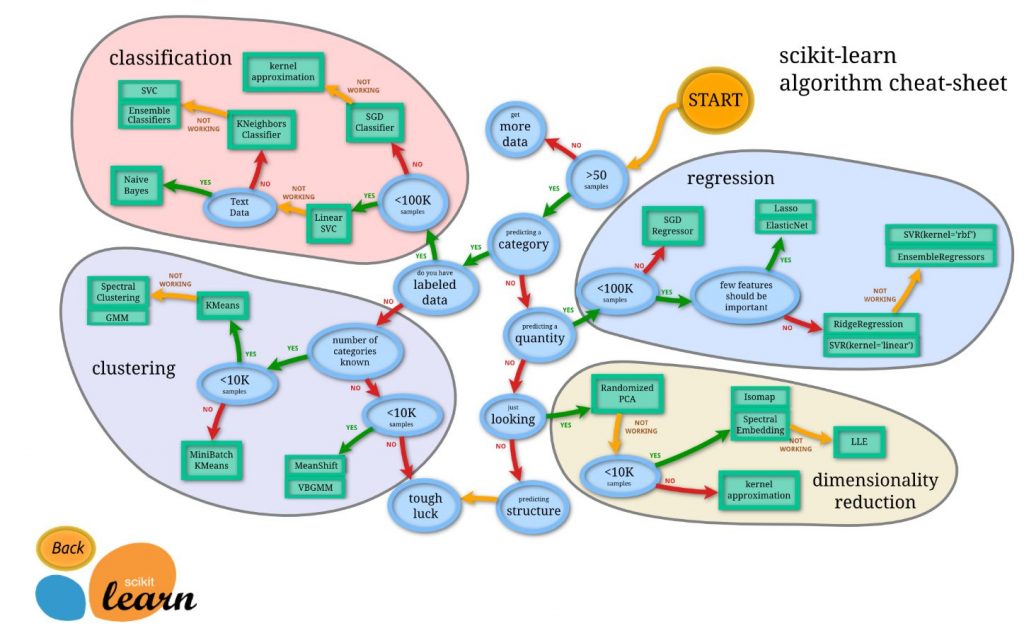
scikit-learnは以下の4つのカテゴリに分かれています。
- 分類(classification)
- 回帰(regression)
- 次元圧縮(dimensionality reduction)
- クラスタリング(clustering)
今回は「回帰(regression)」について紹介していこうと思います。
回帰分析は、データに基づいてある数値を予測することです。
サンプルコード
今回は「重回帰分析」というものを使って、ボストン市の様々な説明変数から適正価格を出します。
公式ドキュメントを参考にしました。
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
1.ライブラリのインポート
今回必要な必要なライブラリをインポートします。
|
1 2 3 4 5 |
import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import Series,DataFrame %matplotlib inline |
2.データのインポート
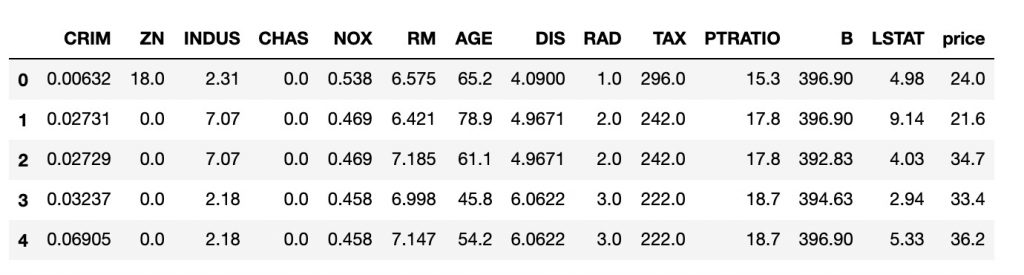
ボストンの住宅情報データなどデータをダウンロードします。
|
1 2 3 4 5 |
from sklearn.datasets import load_boston boston = load_boston() dataset = pd.DataFrame(data = boston['data'], columns = boston['feature_names']) dataset['price'] = boston['target'] dataset.head() |
3.ボストンの住宅データを元に価格を予想する
データを目的変数と説明変数に分ける
|
1 2 3 |
Y = np.array(dataset['price']) X = np.array(dataset[['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']]) |
学習データと検証データに分割。predict()関数で予想。
|
1 2 3 |
from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0) Y_pred = model.predict(X_test) |
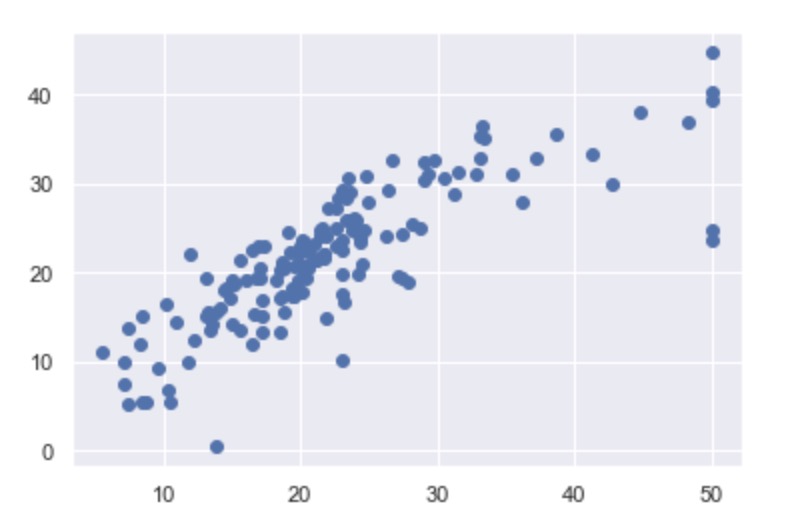
4.グラフで表示
|
1 |
plt.scatter(Y_test, Y_pred) |
まとめ
今回はPythonの機械学習をscikit-learnライブラリを使用し紹介しました。
scikit-learnは様々なことができるのでぜひ調べてみて下さい!
弊社inglowでは、これから広告の運用を考えられている方、あるいはこれから広告代理店に運用をお願いされる方向けに、「業界別Web広告の成功事例」をまとめた資料を無料配布しております。
下記のフォームに入力いただくだけで、無料で資料をダウンロードしていただけます。ぜひご利用下さい。




