



Pythonで文字認識
カテゴリ:Pythonの話
今回はPythonの文字認識エンジン「tesseract」を使って画像の文字を認識させてみます。Djangoを使用してブラウザ上で認識した文字を表示させてみます。
また、弊社ではWebプロモーション成功事例集をまとめた限定資料を無料で配布しています。
Webマーケティングに興味がある方は、下記ページより目を通してみてください。
環境
- Python 3.7.7
- Django 3.0.7
- pyocr 0.7.2
- opencv 4.2.0.34
目次
OCRとは
OCR(Optical Character Recognition/Reader)とは「光学的文字認識」のことです。要するに機械学習した情報を元に画像から文字を検出してくれるソフトウェアのことです。
今回はそのOCRでよく使われるtesseract(テッセラクト)を使用します。tesseractはGoogleが学習させたデータを元に画像から文字を認識してくれます。
インストール
まずは画像ファイルを読み込む為にPillowをインストールします。
|
1 |
pip install Pillow |
次にopencv。opencvは読み込んだ画像の文字をどのように認識してくれたかを確認する為に用います。
|
1 |
pip install opencv-python |
最後にtesseractをインストール。
|
1 |
pip install pyocr |
読み込み処理
ここではDjangoのインストールについては割愛します。導入についてはこちらを参考にしてください。
work/views.py
ここではテンプレートから送られる画像の受け渡しを行っています。
4行目ではこれから作成する文字認識処理を読み込んでいます。
work/ocr/tesseract_img.py
work/urls.py
work/templates/work/work.html
ここまでできたら一度画像ファイルを読み込ませて見てください。私はこちらの画像を使用しました。文字が表示されれば成功です。
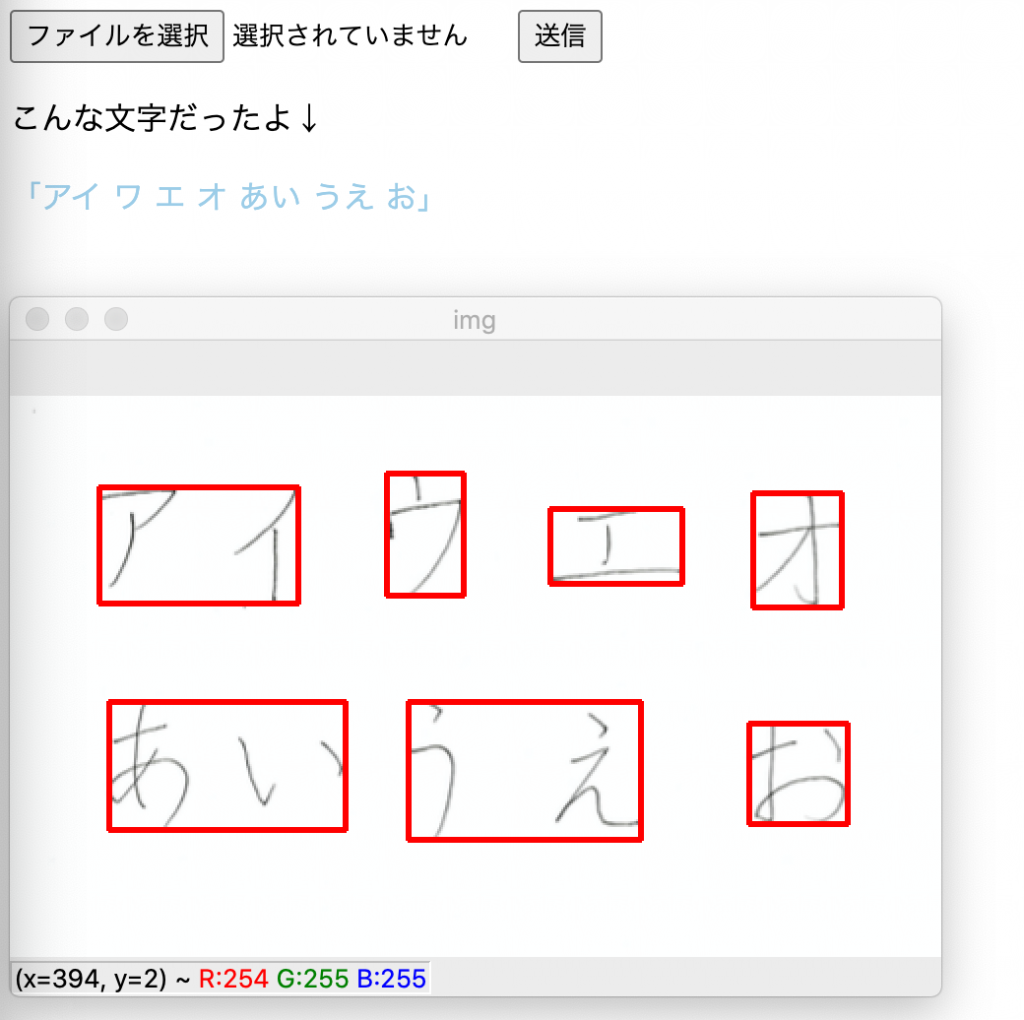
opencvで読み込んだ画像の確認
アプリフォルダと同じ階層に画像フォルダを作成します。
img_tesseract/tesseract/aiueo.jpg
次に先程文字認識をしたファイルに新しくopencvの記述をします。
work/ocr/tesseract_img.py
これでどのように画像が読み込まれたのか赤線部分で確認ができるはずです。
tesseract応用知識
31行目のtesseract_layoutの数字を下記を参考に変えてみてください。それによって認識の精度が上がります。
0: 文字角度の識別と書字系のみの認識(OSD)のみ実施(OCRは実施されない)
1: OSDを利用した自動ページセグメンテーション
2: OSDまたはOCRを利用しない自動セグメンテーション
3: OSDなしの完全自動セグメンテーション(デフォルト)
4: 可変サイズの1列テキストを想定する
5: 縦書きの単一のテキストブロックと想定する
6: 横書きの単一のテキストブロックと想定する
7: 画像を1行のテキストと想定する
8: 画像を1つの単語と想定する
9: 円の中に記載された1単語と想定する(①などの丸数字等)
10: 画像を1文字と想定する
検出パターンの変更もできます。同じく31行目のbuilder=pyocr.builders.「ビルダー」でビルダーの箇所を下記を参考にしてみてください。
TextBuilder 文字列を認識
WordBoxBuilder 単語単位で文字認識 + BoundingBox
LineBoxBuilder 行単位で文字認識 + BoundingBox
DigitBuilder 数字 / 記号を認識
DigitLineBoxBuilder 数字 / 記号を認識 + BoundingBox
tesseractが苦手な画像処理は下記になります。これらに気をつけて読み込み処理をすれば比較的高い精度で読み込んでくれます。
- 文字の間隔が狭い
- 文字以外の背景が含まれている
- 日本語や英語が混在している
おわりに
ビルダーの変更によって数字なども読み込めますので必要に応じて使い分けてみてください。
またwebで集客する方法を別の記事にまとめております。
詳しく解説しているので、web集客について深く知りたい方は、ぜひこちらもご覧ください。

弊社inglowでは、これから広告の運用を考えている方、あるいはこれから広告代理店に運用をお願いされる方向けに、「業界別Web広告の成功事例」をまとめた資料を無料配布しております。
下記の画像をクリック、または、フォームに入力いただくだけで、無料で資料をダウンロードしていただけます。ぜひご利用下さい。




